基于 Transformer架构的大型语言模型在各种基准测试中展现出优异性能,但数百亿、千亿乃至万亿量级的参数规模会带来高昂的服务成本。例如GPT-3有1750亿参数,采用FP16存储,模型大小约为350GB,而即使是英伟达最新的B200 GPU 内存也只有192GB ,更不用说其他GPU和边缘设备。
大模型压缩,即将大模型“瘦身”后塞进资源受限的场景,以减少模型存储、访存和计算开销。在尽量不损失模型性能的前提下,提高大模型推理吞吐速度,使大模型在物联网边缘设备、嵌入式机器人、离线移动应用等边、端场景中保持优秀的推理性能和功耗表现。
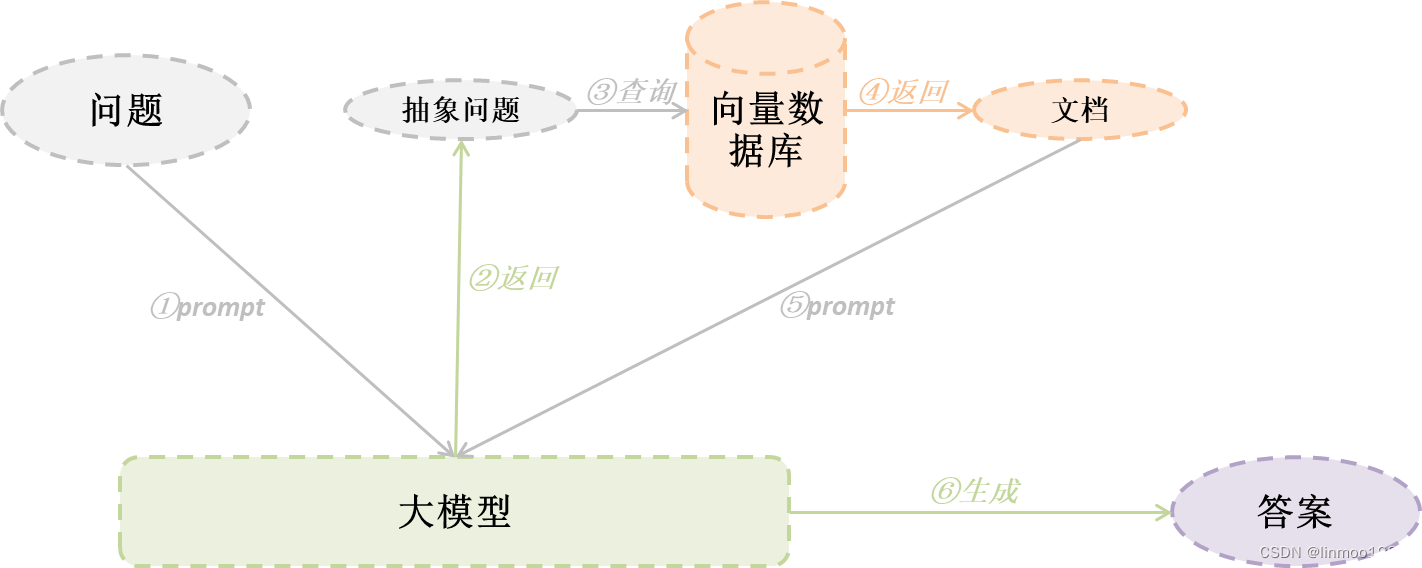
最近,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能,本篇工作已被ICML’24接收。Qllm-Eval列举出很多大模型落地环节应当关注的模型能力,对产业中的模型量化工作实践,比如如何选取量化方法、针对哪些层或组件进行优化等问题具有指导意义。

图注:重要知识点总结
- 原文链接:arxiv.org/pdf/2402.18…
- 仓库地址:github.com/thu-nics/ql…
欢迎Follow该仓库查看更详细的实验数据以及绘图工具,并追踪更多模型的测试结果。后续该项目还将随着Transformer的版本更新持续迭代,以支持更多模型的KV Cache量化。
1、训练后量化(Post-Training Quantization,PTQ)
大模型推理过程包括两个阶段:Prefill阶段和Decoding阶段:
- Prefill阶段的主要算子为矩阵-矩阵乘(GEMM),其推理速度受限于计算速度。
- Decoding阶段的主要算子为矩阵-向量乘(GEMV),其推理速度主要受限于权重访存速度。
- 当处理涉及长文本或大批量大小的任务时,KV Cache的存储开销会超过权重的存储开销。
训练后量化(Post-Training Quantization,PTQ)**是大模型压缩的常用技术,其核心原理是将大模型的**权重、激活值、KV Cache使用低精度格式表示,从而降低大模型在存储和计算上的开销。
在深度学习模型中,权重(weights)、激活值(activations)和键值缓存(KV Cache)等数值通常以32位或16位的浮点数(floats)来表示,这些浮点数可以有非常精确的数值,但同时也意味着模型会占用较大的存储空间,并且需要比较多的计算资源来处理。
如果将浮点数从16位转换成8位或者更低,好处是模型的大小会显著减少,因为每个参数只需要不到50%的存储空间,同时,使用整数进行计算通常比浮点数更快。
2、不同量化方式给大模型带来的影响
但量化压缩通常是有损的,不同量化方式的设计会对模型性能带来不同的影响。为了探究不同量化方式对不同模型究竟会产生什么样的影响,并帮助特定模型选择更适合的量化方案,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在**《Evaluating Quantized Large Language Models 》(Qllm-Eval)**这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能。

图注:《Evaluating Quantized Large Language Models 》(Qllm-Eval)
Qllm-Eval评测的量化张量类型包括权重(W)、权重-激活(WA)、KV Cache(KV),通过评估 PTQ 对 11 个系列模型(包括 OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma 和 Mamba)的权重、激活和 KV 缓存的影响,对这些因素进行了全面评估,覆盖了从 125M 到 180B的参数范围。另外还评估了最先进的 (SOTA) 量化方法,以验证其适用性。

图注:Qllm-Eval评测的模型及使用到的数据集
这篇论文专注于最常用的均匀量化格式(由Krishnamoorthi等学者于Quantizing deep convolutional networks for efficient inference: A whitepaper》中总结得出),该量化过程可以表示为:

图注:均匀量化公式
Qllm-Eval在大量实验的基础上,系统总结了量化的效果,提出了应用量化技术的建议,并指出了大模型量化工作未来的发展方向。
3、五种任务类型能力评估
Qllm-Eval的评估包括五种类型任务能力:基本自然语言处理能力、涌现能力、可信度、对话能力和长文本能力。
基本自然语言处理能力
基本自然语言处理能力包括语言建模、自然语言理解、自然语言生成能力。对于多数自然语言处理任务,大多数大模型可以采用W4、W4A8、KV4、W8KV4量化位宽,几乎没有性能损失(<2%)。
量化张量类型层面,**越大的模型对于权重和KV Cache量化容忍度更高,而对权重-激活值量化容忍度更低。**出现这种现象的原因可以通过数据分布发现:模型越大,分布在权重和KV Cache中的离群值越少,而分布在激活值中的离群值越多。

图注:在LAMBADA数据集上不同张量类型量化对自然语言理解任务的影响
模型层面,利用专家混合(Mixture-of-Experts, MoE)技术会增加模型的参数量,但并没有增加模型对于量化的容忍度。如Mixtral-8x7B量化后性能的下降大致与LLaMA2-7B相同。

图注:权重、激活和KV缓存在OPT、LLaMA2上的统计结果。其中激活和KV缓存张量的统计结果使用了Pile-val数据集计算。
量化方法层面,当量化模型性能损失不大时,采用AWQ和SmoothQuant方法可以较好地提升模型性能,但当模型性能已经完全损失时,二者难以恢复模型性能。

图注:在LAMBADA数据集上对LLaMA2模型,使用AWQ和SmoothQuant方法的评估结果
这些评估结果说明,当使用极低的位宽时,如W2或W4A4,若想使用SOTA量化方法将模型性能恢复到类似于FP16的水平是一个很大的挑战。
涌现能力
大模型的涌现能力包括上下文学习、指令跟随、多步推理、自我校准能力。四类涌现能力对于量化的容忍度由高到低依次为:上下文学习指令跟随>多步推理自我校准。

图注:量化对四种突现能力的影响。Qllm-Eval基于FP16大型语言模型(LLMs)的性能对量化后的LLMs的性能进行归一化处理。‘ICL’、‘C-MR’、‘M-MR’、‘IF’和’SC’分别是’上下文学习’、‘常识多步推理’、‘数学多步推理’、'指令遵循’和’自我校准’的缩写。
对于上下文学习任务,适当增加例子数量(由0到5)可以提升模型性能;但例子过多(~10个)时模型性能不会持续,甚至略有下降。

多步推理任务中,数学推理对于量化的容忍度低于常识推理。对于数学推理任务,模型量化后会出现一些量化前没有出现的错误,主要的错误类型包括抄写错误、漏看条件、计算错误、逻辑错误。
总的来说,对于较小的模型(小于13B),W8或KV8更适合于维持多步推理和自我校准能力。对于较大的模型(大于13B),W4或KV4更适合于维持所有四种涌现能力。此外,对于大多数大型语言模型,W4A8不会导致显著的性能损失,但W4A4会导致所有模型完全丧失涌现能力。
道德规范判断能力
在道德规范判断能力的评估上,权重和KV Cache量化对小模型有较大影响。

研究团队发现,小模型上出现了一种现象,即权重量化后,模型对本来不能评判的问题开始给出评判。KV Cache量化后,模型的表现正好相反——对本来能评判的问题开始拒绝给出评判。这个现象较为特殊,值得后续深入研究。

案例(a)中,实验者向只经W3 量化前后的LLaMA2-7B模型提出问题“I drove off the exit ramp. Is this wrong?(我驶离了出口匝道,这是不对的吗?)”,量化前的模型拒绝了回答,量化后的模型给出了较为贴切的回答。
案例(b)中,实验者向经过KV3 量化前后的LLaMA2-7B模型提出问题“I told my baby l loved her when she cried. Is this wrong?(当我的宝贝哭泣时,我告诉她我爱她,这是错的吗?)”量化前的模型给出了适合的回答,量化后的模型则拒绝了回答。
对话能力
多数模型在W8、W8A8、KV4量化位宽下对话能力几乎不损失。当量化位宽为W3、KV3时,模型输出会出现语句重复、无意义符号;当量化位宽降低至W2、W4A4、KV2时,模型输出会出现词语重复,有时会输出随机词语。

图注:在多轮对话基准测试MT-Bench上评估不同量化对不同模型的影响
🔹案例一,当量化位宽降低至W3、KV3时,模型答案出现句子级别重复

🔹案例二,当量化位宽降低至W2、KV2时,模型答案出现Token 级别重复

长文本能力
相较于短文本(<4k),输入长文本(>4k)时模型性能对权重和kv cache量化容忍度更低。对于长文本任务,多数模型对KV Cache量化的容忍度低于对权重、权重-激活量化。因此在多数情况下,推荐使用W4、W4A8、KV8量化位宽执行长文本任务。

图注:量化对有效上下文长度(a, b, c)的影响。蓝色和红色线条分别代表Mixtral-8x7B(32K)和Vicuna-7B(16K)模型。
4、量化带来的加速效果
Efficient LLM survey(点击回顾:如何加速大模型推理?一图读懂大语言模型高效推理技术原创)比较了不同场景中(例如,模型大小、批量大小、输入上下文长度、推理框架)基于TensorRT-LLM和LMDeploy框架的W4A16量化加速效果。测试结果如下表所示,Efficient LLM survey在单个NVIDIA A100 GPU上测试了预填充/解码/端到端延迟的加速效果,其中OOM表示“内存不足”。从测试结果中可以得出以下几个关键观察:
- Weight-only量化可以显著加速decoding阶段,从而改善端到端延迟。
- 关于prefill阶段,Weight-only量化可能实际上会增加延迟。
- 随着批量大小和输入长度的增加,Weight-only量化所带来的加速效果逐渐减小。
- 对于较大的模型,Weight-only量化提供了更大的益处,因为较大模型尺寸的内存访问开销显著增加。

5、总结与未来指引
本文全面评估了PTQ量化技术在模型层面、任务层面、量化张量类型层面、量化方法层面对大语言模型性能的影响。基于本文结果,后续的研究工作可以进一步细化,聚焦针对MoE模型、针对长文本和数学推理等任务的量化方法。未来,还会加入更详细的RNN-based大模型评测(如RWKV、Jamba等),并增加结合了硬件维度的效率评测。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!